
一套 SQL 搞定多平台数据?广告数据分层架构实战指南
7/14/2025
如果你正在做广告投放相关的数据工作,一定遇到过这样的场景:抖音、快手、腾讯广告等平台的数据格式完全不同,每次做跨渠道分析都要重新写 SQL,业务方催报表你却还在处理数据格式……
今天和大家分享一套经过实战检验的数据分层方案,希望能帮你告别这些烦恼。
为什么数据总是这么乱?
想象一下,你的公司投放了抖音、快手、腾讯等多个广告渠道,但同样是「广告计划」的 ID 这个概念,抖音叫「项目 ID」,快手叫「推广计划 ID」,腾讯叫「活动 ID」。当业务部门要一个 ROI 报表时,你需要写 3 套不同的 SQL 去处理这些字段差异。新来的同事每次都要重新理解各种字段含义,一个简单的跨渠道对比变得复杂无比。
更要命的是数据不一致的问题,这个报表显示 100 万,那个报表显示 120 万,到底哪个是对的?这些都是缺乏数据分层架构而导致的典型问题。
分层架构的本质是把数据整理得像超市货物一样有条理。一楼是仓库,什么都有但比较乱;二楼是分类整理区,同类商品放一起;三楼是 DIY 组合区,提供各种套装材料但需要顾客自己组装;四楼是成品专柜,拿了就能直接用。
这分别对应数仓概念中:
- ODS 层像仓库:各种商品混放,没有分类整理;
- DWD 层像分类整理区:按商品类型整理,食品、日用品、电器分开放;
- DWS 层像 DIY 组合区:按需求配好套装材料,装修套装、烹饪套装等,但顾客还需要自己组装使用;
- ADS 层像成品专柜:直接拿走就能用的完成品,比如做好的便当、组装好的家具。
通过这种分层方案,我们实现了一次标准化、到处复用的效果。新人上手变快了,只需要学会一套标准化规则;开发效率提高了,复杂逻辑下沉到底层;数据口径统一了,再也不会出现不同报表数据打架的情况。
掌握分层的核心思维
数据分层的核心在于职责分工明确。ODS 层只管存储,不做任何处理;DWD 层只管清洗标准化,不做业务聚合;DWS 层只管业务建模,不做具体应用;ADS 层直接服务业务需求。这种单向依赖的关系保证了系统的稳定性,上层使用下层,下层不感知上层的存在。
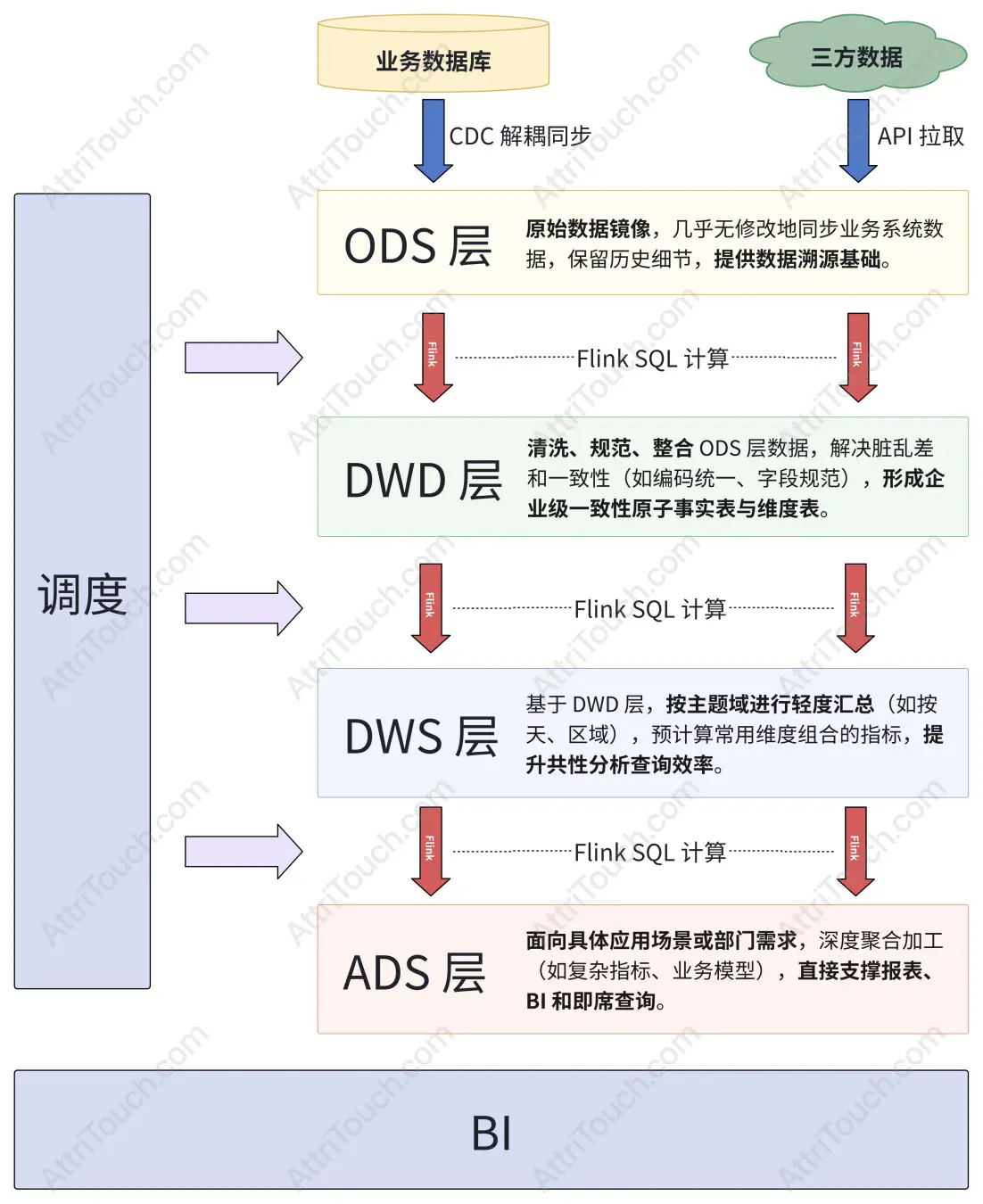
在数据传递过程中,我们坚持宁多勿少的原则。因为数据一旦丢失就很难恢复,而冗余的数据可以在后续过程中进行优化。设计每一层时,我们需要反复思考三个问题:
- 这一层的职责边界在哪里?
- 依赖上层什么数据?
- 要向下层提供什么服务?
只有明确了这些问题,才能设计出真正有用的数据架构。
ODS 层:数据的「保险箱」
ODS 层的设计理念是「照单全收」,且就要像银行保险箱一样,原样存储,绝不修改。我们要保持数据的原汁原味,无论是 JSON 格式的 API 回调,还是 CSV 格式的文件上传,都按照原始格式存储。这样做的好处是字段或者内容发生变化时,有完整的记录可以追溯。并且在新增字段时方便扩展。
以抖音广告回调为例,原始数据包含 projectId、projectName、cost 等字段,我们就直接以 JSON 格式存储在 original_data 字段中,同时记录用户 ID 和创建时间。这种设计支持多样化的数据源,不管是结构化的数据库数据、半结构化的日志文件,还是非结构化的素材信息,都能很好地兼容。
实际案例:ODS 层建表示例
-- ODS 层:抖音广告原始数据表 CREATE TABLE ods_douyin_ad_callback ( id BIGINT, user_id VARCHAR, original_data TEXT, -- 存储完整 JSON 数据 source_type VARCHAR, -- 数据来源:douyin/kuaishou/tencent created_time TIMESTAMP, partition_date VARCHAR -- 分区字段 ) PARTITIONED BY (partition_date); -- 数据插入示例 INSERT INTO ods_douyin_ad_callback VALUES ( 1001, 'user123', '{"projectId":"abc123","projectName":"春节推广","cost":1500.0,"clicks":300,"conversions":15,"timestamp":"2024-01-15 10:30:00"}', 'douyin', '2024-01-15 10:30:00', '20240115' );
当上层数据出现问题时,我们可以快速回到 ODS 层查找原因,这种便于追溯的特性在实际工作中非常重要。很多时候,业务方质疑数据准确性,我们需要能够证明数据的来源和处理过程。
DWD 层:数据的「翻译官」
DWD 层承担着统一标准的重要任务,就像把各种「方言」翻译成「普通话」。这一层的主要工作包括字段标准化,将抖音的 projectId、快手的 planId、腾讯的 campaignId 都统一为 ad_campaign_id。同时进行格式统一,把抖音的时间戳格式和快手的字符串时间格式都转换为标准的 datetime 格式。
数据清洗也是这一层的重要职责,包括去除重复记录、过滤测试账号数据、补全必要字段等。在实际操作中,我们建议建立映射规则表而不是硬编码,这样当新增渠道或字段变更时,只需要更新配置表即可。
实际案例:DWD 层数据清洗和标准化
-- DWD 层:广告投放成本表 CREATE TABLE dwd_ad_cost_info ( ad_campaign_id VARCHAR, -- 统一的广告计划 ID ad_campaign_name VARCHAR, -- 统一的广告计划名称 ad_channel VARCHAR, -- 渠道:douyin/kuaishou/tencent cost_amount DECIMAL(10,2), -- 统一的成本金额 click_count INT, -- 点击数 conversion_count INT, -- 转化数 stat_date DATE, -- 统计日期 create_time TIMESTAMP, -- 创建时间 source_table VARCHAR, -- 源表名 source_id VARCHAR -- 源记录 ID ) PARTITIONED BY (stat_date); -- 从 ODS 层清洗数据到 DWD 层 INSERT INTO dwd_ad_cost_info SELECT CASE WHEN source_type = 'douyin' THEN JSON_EXTRACT(original_data, '$.projectId') WHEN source_type = 'kuaishou' THEN JSON_EXTRACT(original_data, '$.planId') WHEN source_type = 'tencent' THEN JSON_EXTRACT(original_data, '$.campaignId') END AS ad_campaign_id, CASE WHEN source_type = 'douyin' THEN JSON_EXTRACT(original_data, '$.projectName') WHEN source_type = 'kuaishou' THEN JSON_EXTRACT(original_data, '$.planName') WHEN source_type = 'tencent' THEN JSON_EXTRACT(original_data, '$.campaignName') END AS ad_campaign_name, source_type AS ad_channel, CAST(JSON_EXTRACT(original_data, '$.cost') AS DECIMAL(10,2)) AS cost_amount, CAST(JSON_EXTRACT(original_data, '$.clicks') AS INT) AS click_count, CAST(JSON_EXTRACT(original_data, '$.conversions') AS INT) AS conversion_count, DATE(created_time) AS stat_date, created_time AS create_time, 'ods_douyin_ad_callback' AS source_table, CAST(id AS VARCHAR) AS source_id FROM ods_douyin_ad_callback WHERE partition_date = '20240115' AND JSON_EXTRACT(original_data, '$.cost') IS NOT NULL -- 过滤异常数据 AND user_id NOT LIKE 'test_%'; -- 过滤测试账号
按业务维度分表是 DWD 层的另一个重要策略。我们将用户属性、投放成本、转化数据分别存储,而不是放在一张大表中。这样既保证了每张表的职责单一,也提高了查询性能。每条记录都要保留数据来源信息,包括源表名、源记录 ID、处理时间等,这为后续的问题排查提供了重要依据。
DWS 层:业务的「建模师」
DWS 层是技术数据向业务信息转换的关键层级。它的核心价值在于避免重复计算,将常用的业务指标进行预计算。比如用户维度的注册时间、付费金额、生命周期价值,素材维度的投放成本、转化数、ROI,活动维度的整体效果和渠道对比等。
这一层还负责统一业务口径,确保所有业务方使用相同的数据定义。什么是新用户?定义为当天注册的用户。什么是付费用户?定义为有过付费行为的用户。什么是 ROI?定义为收入除以成本。这些看似简单的定义,在实际工作中往往容易产生分歧,DWS 层的作用就是提前统一这些标准。
实际案例:DWS 层业务建模宽表
-- DWS 层:广告效果宽表 CREATE TABLE dws_ad_effect_daily ( stat_date DATE, ad_channel VARCHAR, ad_campaign_id VARCHAR, ad_campaign_name VARCHAR, -- 成本指标 total_cost DECIMAL(10,2), avg_cost_per_click DECIMAL(6,2), -- 流量指标 total_impressions BIGINT, total_clicks BIGINT, click_rate DECIMAL(6,4), -- 点击率 = 点击数/展示数 -- 转化指标 total_conversions INT, conversion_rate DECIMAL(6,4), -- 转化率 = 转化数/点击数 cost_per_conversion DECIMAL(8,2), -- CPA = 成本/转化数 -- 收入指标(关联用户付费数据) total_revenue DECIMAL(10,2), roi DECIMAL(6,2), -- ROI = 收入/成本 -- 用户指标 new_user_count INT, -- 新用户数 active_user_count INT, -- 活跃用户数 create_time TIMESTAMP ) PARTITIONED BY (stat_date); -- DWS 层数据聚合逻辑 INSERT INTO dws_ad_effect_daily SELECT a.stat_date, a.ad_channel, a.ad_campaign_id, a.ad_campaign_name, -- 成本数据聚合 SUM(a.cost_amount) AS total_cost, CASE WHEN SUM(a.click_count) > 0 THEN SUM(a.cost_amount) / SUM(a.click_count) ELSE 0 END AS avg_cost_per_click, -- 流量数据聚合 SUM(t.impression_count) AS total_impressions, SUM(a.click_count) AS total_clicks, CASE WHEN SUM(t.impression_count) > 0 THEN SUM(a.click_count) * 1.0 / SUM(t.impression_count) ELSE 0 END AS click_rate, -- 转化数据聚合 SUM(a.conversion_count) AS total_conversions, CASE WHEN SUM(a.click_count) > 0 THEN SUM(a.conversion_count) * 1.0 / SUM(a.click_count) ELSE 0 END AS conversion_rate, CASE WHEN SUM(a.conversion_count) > 0 THEN SUM(a.cost_amount) / SUM(a.conversion_count) ELSE 0 END AS cost_per_conversion, -- 收入数据关联 COALESCE(SUM(r.revenue_amount), 0) AS total_revenue, CASE WHEN SUM(a.cost_amount) > 0 THEN COALESCE(SUM(r.revenue_amount), 0) / SUM(a.cost_amount) ELSE 0 END AS roi, -- 用户数据统计 COUNT(DISTINCT CASE WHEN u.is_new_user = 1 THEN u.user_id END) AS new_user_count, COUNT(DISTINCT u.user_id) AS active_user_count, CURRENT_TIMESTAMP AS create_time FROM dwd_ad_cost_info a LEFT JOIN dwd_ad_traffic_info t ON a.ad_campaign_id = t.ad_campaign_id AND a.stat_date = t.stat_date LEFT JOIN dwd_user_revenue_info r ON a.ad_campaign_id = r.source_campaign_id AND a.stat_date = r.pay_date LEFT JOIN dwd_user_info u ON r.user_id = u.user_id WHERE a.stat_date = '2024-01-15' GROUP BY a.stat_date, a.ad_channel, a.ad_campaign_id, a.ad_campaign_name;
宽表思维是 DWS 层的核心设计理念。我们将素材的成本数据、转化数据、自然量数据整合到一张表中,将用户的基础属性、行为数据、付费数据合并存储。这样一张表就能支持按渠道分析、按时间分析、按素材分析等多个维度的业务需求。
在指标设计中,我们采用三级分层架构:
- 原子指标(基础数据层):不可再分的直接度量,如点击量、成本;
- 派生指标(条件组合层):由原子指标 + 维度、周期构成,如点击率 = 点击量 / 展示量(需明确统计范围,如「近 7 天首页点击率」);
- 复合指标(计算逻辑层):通过公式组合原子、派生指标,如 ROI = 收入 / 成本。
这种分层方式既保证了指标体系的完整性,又通过明确的计算层级提升了可解释性。
ADS 层:业务的「直通车」
ADS 层是数据服务的最后一公里,直接面向业务需求。它主要服务三类场景:业务报表、实时监控和数据产品。
业务报表包括日报、周报、月报等常规分析需求。日报展示昨日投放概览,周报进行渠道 ROI 对比,月报分析趋势变化。实时监控则关注成本异常预警、新素材效果跟踪、预算消耗监控等实时性要求较高的场景。数据产品层面,我们可以基于历史数据提供投放优化建议,进行用户价值评估,展示素材效果排行等。
实际案例:ADS 层应用场景
-- 场景 1:每日投放效果报表 CREATE TABLE ads_daily_report AS SELECT stat_date, ad_channel AS '渠道', COUNT(DISTINCT ad_campaign_id) AS '投放计划数', SUM(total_cost) AS '总成本', SUM(total_clicks) AS '总点击', SUM(total_conversions) AS '总转化', ROUND(AVG(click_rate) * 100, 2) AS '平均点击率(%)', ROUND(AVG(conversion_rate) * 100, 2) AS '平均转化率(%)', ROUND(SUM(total_revenue) / SUM(total_cost), 2) AS '整体 ROI' FROM dws_ad_effect_daily WHERE stat_date = CURRENT_DATE - 1 GROUP BY stat_date, ad_channel ORDER BY SUM(total_cost) DESC; -- 场景 2:ROI 排行榜(供优化师参考) CREATE TABLE ads_roi_ranking AS SELECT ad_campaign_name AS '广告计划', ad_channel AS '渠道', total_cost AS '成本', total_revenue AS '收入', roi AS 'ROI', CASE WHEN roi >= 3.0 THEN '优秀' WHEN roi >= 1.5 THEN '良好' WHEN roi >= 1.0 THEN '盈利' ELSE '亏损' END AS '效果评级' FROM dws_ad_effect_daily WHERE stat_date BETWEEN CURRENT_DATE - 7 AND CURRENT_DATE - 1 AND total_cost >= 1000 -- 筛选成本较高的计划 ORDER BY roi DESC LIMIT 50; -- 场景 3:成本预警监控 SELECT ad_campaign_name, ad_channel, total_cost, total_cost / 7 AS '日均成本', CASE WHEN total_cost > 10000 THEN '高消耗预警' WHEN roi < 0.8 THEN 'ROI 过低预警' WHEN cost_per_conversion > 100 THEN 'CPA 过高预警' ELSE '正常' END AS '预警状态' FROM dws_ad_effect_daily WHERE stat_date = CURRENT_DATE - 1 AND (total_cost > 10000 OR roi < 0.8 OR cost_per_conversion > 100); -- 场景 4:渠道效果对比分析 SELECT '近7天' AS '时间范围', ad_channel AS '渠道', SUM(total_cost) AS '总成本', SUM(total_revenue) AS '总收入', ROUND(SUM(total_revenue) / SUM(total_cost), 2) AS 'ROI', SUM(new_user_count) AS '新增用户', ROUND(SUM(total_cost) / SUM(new_user_count), 2) AS '获客成本' FROM dws_ad_effect_daily WHERE stat_date BETWEEN CURRENT_DATE - 7 AND CURRENT_DATE - 1 GROUP BY ad_channel ORDER BY SUM(total_revenue) / SUM(total_cost) DESC;
ADS 层的设计要点是面向具体场景,每个表都对应明确的业务需求。ads_daily_report 服务日报需求,ads_roi_ranking 提供ROI排行,ads_user_analysis 支持用户分析。同时要降低使用门槛,让业务同学可以直接查询,无需复杂的 JOIN 操作。
性能优化也是 ADS 层的重要考虑因素。通过合理的分区设计、索引配置、缓存策略,确保查询响应速度能够满足业务需求。
如何确保成功落地?
分层架构的成功实施需要组织、技术、运营三方面的保障。
组织保障方面:需要明确分工和建立规范。数据工程师负责 ODS 和 DWD 层的建设,数据开发负责 DWS 层的业务建模,数据分析师负责 ADS 层的应用开发,业务专家负责需求确认和业务逻辑验证(当然一人身兼数职也是很常见的 (๑•̀ㅂ•́)و✧)。同时要建立流程规范,新增字段必须先在 DWD 层标准化,新增指标必须先在 DWS 层定义口径,新增应用必须基于现有数据开发。
技术保障方面:数据质量监控至关重要。我们需要监控每日数据量是否正常,关键字段是否有异常,各层数据是否及时更新。性能优化包括合理的分区策略设计、不同层级的差异化资源配置、根据业务需求设置合适的刷新频率等。
运营保障方面:文档管理和培训体系缺一不可。字段字典要说明每个字段的具体含义,变更日志要记录改动的影响范围,使用手册要指导如何高效使用数据。培训方面,要对新人进行分层理念培训,对业务方进行正确使用方法培训,定期组织最佳实践分享。
新人实操指南
对于刚接触数据分层的新人,建议按照五个步骤循序渐进。
第一步是搞懂业务:不要急着写代码。要理解完整的业务流程,从用户看到广告、点击广告到最终付费的整个路径。了解不同角色的需求差异,优化师关心成本效率,分析师关心数据准确性,产品经理关心用户转化。掌握核心指标的业务含义,ROI、CPI、LTV 等指标背后的计算逻辑和业务价值。
第二步是摸清数据:了解各个数据源的特点。数据格式可能是 JSON、CSV 或数据库表,更新频率可能是实时、小时级或天级,数据质量方面要知道哪些字段可能为空、哪些数据需要特殊处理。
第三步是设计分层方案:从下往上逐层设计。先确定 ODS 层的存储方式和分区策略,再制定 DWD 层的标准化规则,然后设计 DWS 层的宽表结构,最后明确 ADS 层的应用场景。
第四步是小步快跑:不要贪图一次性解决所有问题。先搞定核心业务场景,确保主要需求得到满足,再逐步补充边缘需求,基于使用反馈持续优化改进。
第五步是沉淀规范:在实践过程中总结经验。建立命名规范、开发流程、运维标准等,为团队的长期发展奠定基础。
写在最后
数据分层不只是技术方案,更是一种思维方式。它教会我们化繁为简,将复杂的业务问题拆解成简单的技术任务;坚持标准优先,统一的标准比个性化实现更重要;进行长远考虑,今天的架构设计要为明天的扩展需求留出空间;始终服务业务,技术是手段,业务价值是目的。
好的数据架构是业务成功的基石,而分层设计是数据架构的核心。希望本文这些 SQL 示例能帮助你更好地理解和实践数据分层架构,从理论走向实际应用。记住,最好的架构不是最复杂的,而是最适合业务需要的。