
小公司如何自己搭建广告 BI 系统?(上)
6/24/2025
引言
现在广告投放已成为小公司获取客户、实现增长的生命线。然而,如何有效评估广告成效、优化投放策略,是小公司的一大难题。
大多数小公司的广告投放团队在评估成效时,市场或运营人员会从各个广告平台(如 Google Ads、Meta Ads 等)手动拉取广告效果数据。这些数据通常以 Excel 或 CSV 表格的形式导出,随后被统一汇总到一个庞大的主 Excel 表格中进行分析,最终可能形成一个自动化计算的脚本,拉取好数据源后使用脚本自动处理好,这种方式的弊端毋庸置疑,实时性、准确性、稳定性都无法保证。
如果公司开发资源比较充足,会让 IT 部门介入,通过调用各个广告平台的 API 来自动拉取数据。随后,这些数据会被导入到统一的数据仓库(如 MySQL、PostgreSQL、Google BigQuery 等),并在此基础上搭建定制化的数据看板。开发的方式实现比较多样化,这里优势弊端不能一概而论。
但无论如何实现广告报表,我们都需要面临几个问题:
- 如何分配好不同渠道的数据?
- 如何保证实时性?
- 如何与业务关联起来(归因分析)?
- 如何定义有效的指标?
- 如何低成本搭建?
本文将会围绕这几个方向,用实战经验一步步介绍BI 搭建的流程。
数据收拢
做好的广告 BI 的第一步就是做好数据收拢,广告这个业务域的数据主要分三块:
广告媒体的数据
这里主要指 Google Ads、Meta Ads(Facebook)、SnapChat 等广告平台提供的广告报表数据,官方会给授权的账号拉取报表的权限,可以直接通过 Marketing API 拉取,平台申请授权比较麻烦,如果实在拿不到权限可以花点钱使用三方平台(如 AppsFlyer,Winsdor),上篇文章 《广告BI第一步,从告别手动拉数据开始(丰俭由人版)》 有详细讲述如何完成广告数据的拉取,不清楚的可以仔细看下。
如果是做海外,广告报表推荐拉取到 Ad + Country 层级,广告的数据一般到这个层级就够用了。比较常用的指标有:安装、点击、消耗、展示、还有一些期群指标。
Tips:广告 BI 虽然也能拿到用户回收等数据,但并不准确,特别是在投多个渠道的情况下。
用户广告归因数据
用户广告归因数据是业务与广告效果相互连接的纽带,知道了用户是哪个广告过来的我们才能和业务结合起来深入分析。
国内归因可以自己做,因为能拿到广告触点的数据(通过触点中携带的设备信息归因)。但海外需要依赖 MMP(第三方广告监测合作伙伴),海外的推广平台一般是不给广告主开发者开放用户广告触点的。
海外做的比较大的两家归因平台是 Adjust 和 Appsflyer。如果想做做海外广告 BI,这点钱是必不可少的。
业务数据
业务数据是广告决策分析的关键,也是企业数据决策的中心。业务数据的收拢是工作量最大的部分,需要专门做一个数仓,这部分内容我放到下一节具体讲。
数据仓库建设
看到这里可能有人要问不是做 BI 吗?怎么就开始做数据仓库了,不是说好低成本建设的吗?实际上数据仓库只是一个概念,不同的业务规模可以选用不同的方式实现,无需太担心成本问题。
先解释一下做数仓的原因:目前大多数互联网公司都采用的微服务架构,数据可能分不同的节点或不同的存储介质(MySQL、Redis、Kafka、MongoDB)存储,这些数据想拿到一起去运算,用传统业务的方式肯定是非常复杂的,可能开发一个复杂字段都需要一天的时间。而数据仓库的作用就是将这些不同来源不同结构的数据做收拢清洗,统一处理。
对于我们广告业务来说也是一样的,如果广告数据存在 Excel、归因数据存在 MongoDB、用户数据又存在 MySQL,这时候如果用传统方式做起来,费时费力,而且长期下去并不好维护。
数仓建设核心主要分五块:存储、计算、调度、展示(BI)、管理(数据字典)。数据管理这里我不重点论述(后面单独开一章),我主要从存储、计算、调度、展示这四块来给大家推荐几种数仓的搭建技术选型。
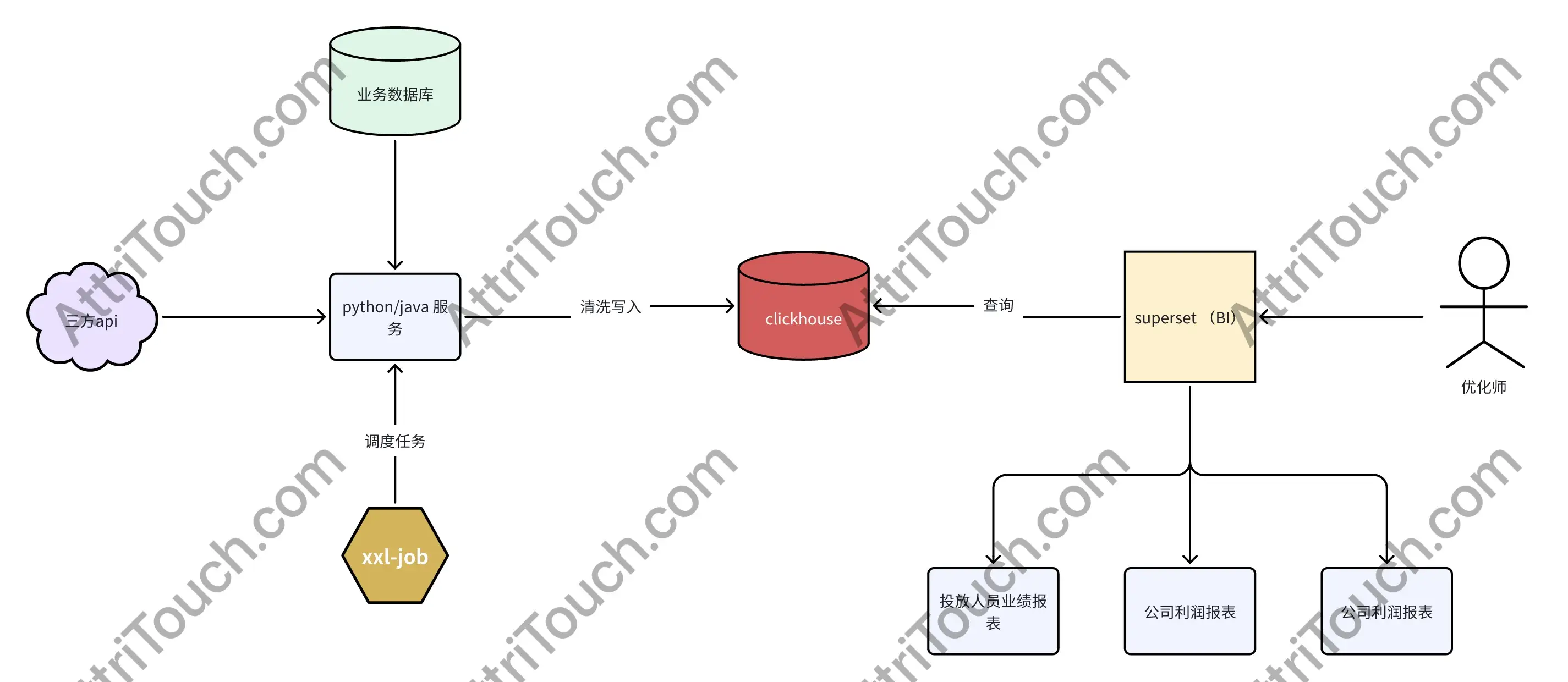
方案一
- 存储层:ClickHouse
- 计算层:Python/Java
- 任务调度:xxl-job
- BI 层:Superset
优势
- ClickHouse 专为 PB 级数据 OLAP 设计,具备列式存储、向量化引擎和并行处理能力,查询响应可达亚秒级。
- Superset 提供丰富的可视化组件,支持零/低代码创建看板,连接多种数据源,支持用户自助进行探索性分析(筛选、下钻、聚合等)。
- ClickHouse 支持高效数据摄入,可实现准实时分析(前提是计算层能进行高效的近实时 ETL)。
- 运维成本低:ClickHouse 和 Superset 都是开源的,企业可以自己部署构建,基本都是开箱即用。
缺点
- 计算层瓶颈:ETL 和数据预处理逻辑依赖 Python/Java 服务,处理大规模、复杂逻辑任务时仍是性能和开发效率的瓶颈。
- 任务调度与管理困难:对于包含多步骤(如:拉取三方数据 -> 关联业务库 -> 复杂清洗 -> 入库)的 ETL 流程,缺乏统一可靠的调度框架。节点失败可能导致大量冗余重跑,任务复杂度和失败影响增大。
- 无法达到实时化的要求:依赖 xxl-job 调度,每次数据处理都是批处理,数据无法实时计算完成。
总结:如果业务规模较小(数据在 TB 级别),不想花大价钱买 BI 工具和数据库的话,可以选择这个方案,应对 TB 级别的数据十分轻松,基本能达到亚秒级别。
Superset 这个开源 BI 工具也十分好用,只需要简单拖拽就能完成 BI 搭建,而且最新版的支持数据下钻,只要将不同视角的面板搭起来,设置字段关联就可以了。
这个方案最麻烦的就是任务调度,但是如果只有一个业务域的话,用 xxl-job 足够用。如果不缺运维资源的话可以再部署一套 DolphinScheduler,这个组件可以通过工作流的方式将不同节点不同方式的任务(Flink、Python、SQL ……)统一调度起来。
方案二
- 存储层:
- 结构化数据:ClickHouse
- 非结构化数据:HDFS/OSS
- 计算层:Flink(流批一体计算引擎)
- BI 层:Superset
- 任务调度层:DolphinScheduler/Airflow(分布式工作流任务调度系统)
方案简介:这个方案完全按照数仓模型构建的数据仓库,相较于上个方案复杂度会成倍增加,但实时性、稳定性、可扩展性都可以得到保证,完全能够承受 PB 级别的数据。
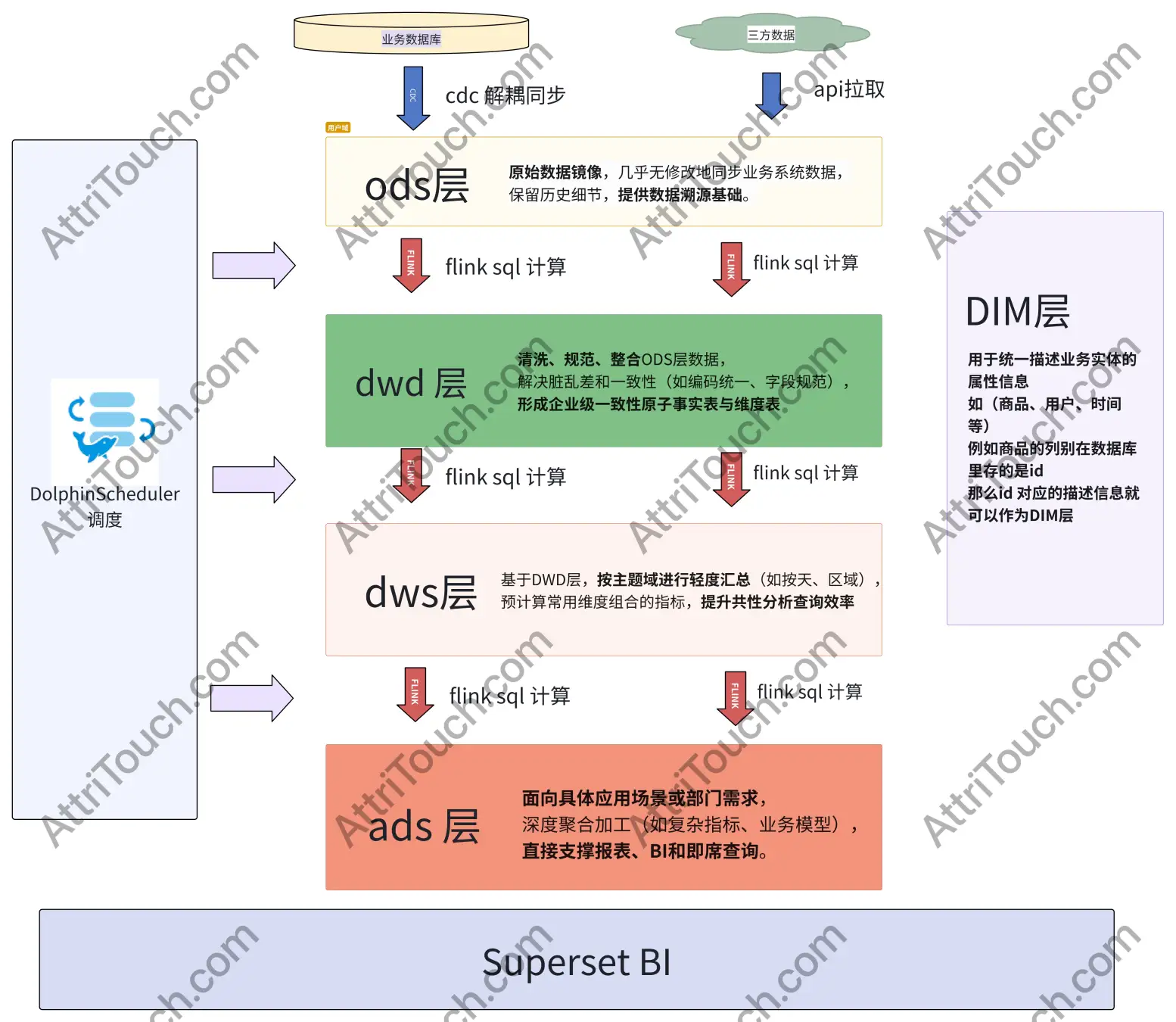
优势
- 强大的计算能力:Flink 引擎提供高吞吐、低延迟的流处理和高效的批处理能力,轻松应对 TB/PB 级数据计算,代码更简洁高效,性能远超原生代码。
- 流批一体化:一套代码可同时处理实时流数据和历史批量数据,简化开发和维护,实现真正的实时/近实时 BI。
- 精细化调度管理:DolphinScheduler/Airflow 等工具提供可视化 DAG 编排、任务依赖管理、失败重试与告警、历史记录追溯等,极大提高复杂数据管线的可靠性和运维效率。
- 架构扩展性高:数据存储层可按需选择最佳组件(如 Kafka 实时接入、Hologres 高性能 OLAP、HDFS/OSS 海量存储),计算引擎(Flink)可分布式水平扩展。
- 数据模型规范化:构建数仓模型,从源头统一指标定义和计算逻辑,确保数据一致性和准确性。
缺点
- 复杂度最高:涉及大数据生态多个组件的集成、开发和运维,技术门槛高。
- 整体成本最高:对硬件资源、专业人才和运维投入要求最高。
- 实施周期长:需要较长时间进行技术选型、架构设计、开发和调优。
Tips:为什么第一个方案不使用数仓模型呢?
从图中可以看到数仓模型是需要分多层的,这就涉及到很多个调度任务,最不仅会让开发量变多,各层任务的稳定性也需要保证,只使用 xxl-job 调度和 Python 计算是满足不了要求的。
所以如果业务量较小且不需要构建复杂的广告域 BI,还是推荐第一个方案。
方案三
如果觉得第一个方案无法满足要求,第二个方案又太复杂,可以试试方案三,也是我们在用的方案。
- 存储层:
- 结构化数据:ClickHouse/Hologres
- 非结构化数据:HDFS/OSS
- 计算层:Hologres 动态表
- 数据抽取:Flink CDC + Python
- BI 层:Superset
- 任务调度:Hologres + xxl-job
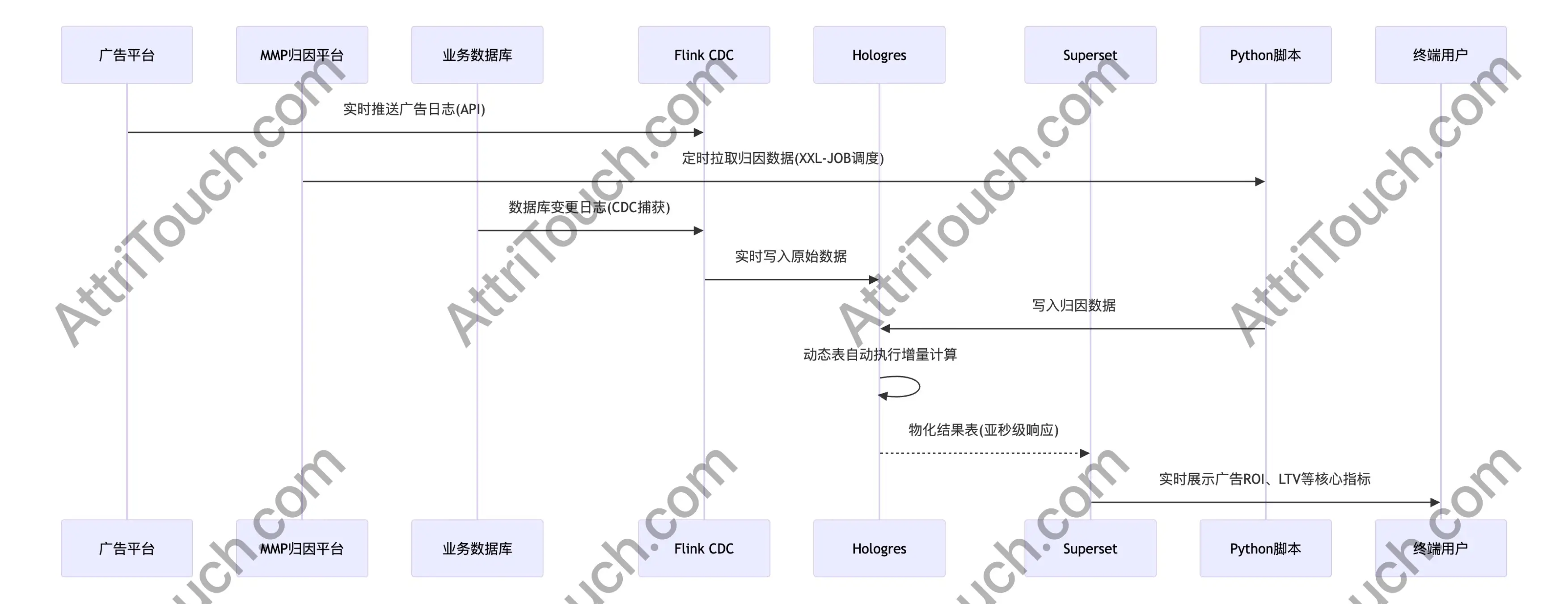
方案简介:这个方案主要基于 Hologres 的动态表功能,Hologres 动态表可以直接通过定义 SQL 形成物化视图(直接生成一个物理表),并自动调度任务(可以自由设置调度时间),同步方式支持全量模式和增量模式,数据延迟可以达到秒级(准实时)。
基于这个能力我们就可以省略掉不少各层之间数据同步的 Flink 任务开发过程,也可以免去任务调度的麻烦。
我们需要考虑的主要是怎么将源数据同步到 Hologres 中,这里选用了 Flink CDC 来实时同步业务数据库的数据,Python/Java 服务来拉取三方 API 的报表数据同步到 Hologres 中,xxl-job 在这里的作用也是为了调度拉取三方 API 任务。
如果有非结构化数据处理,可以再使用 Flink 进行计算。
这个方案的缺点主要有三个:
- 实时性:不能达到 ms 级表的实时,最多能达到秒级别的准实时。
- 动态表无法加字段:这个问题是使用中最麻烦的问题,动态表建好之后只能修改 SQL 定义(SQL 定义返回的字段要与动态表中的字段一致),不能新增字段。如果业务突然想在某一个 DWS 表新增一个 ODS 层也没有来源的字段,那就非常痛苦了,你只能选择新建一张表,或者从头开始删表重建(不推荐)。
- 费用昂贵:Hologres 存储和计算是分开收费的,而计算资源最低规格 32CPU。每年的费用还是比较贵的。
业务流程
本文未完待续,下一篇继续讲解 广告 BI 系统中的「指标建设」和「指标管理」。